Source: https://dzone.com/articles/migrating-to-microservices
This article details the steps to migrate an existing monolithic application to microservices, an architectural approach that consists of building systems from small services, each in their own process, communicating over lightweight protocols. This will provide a broad view of microservices implementation in Azure using service fabric, challenges faced in migration, approaches, and strategies that we can implement, and ways to build, release, monitor, and scale microservices.
This article deals with an innovative practice that has the potential to be used across different projects.
Microservices are loosely coupled components by independent teams using a variety of languages and tools. Speed and flexibility far outweigh the disadvantages. We will use Azure Service Fabric to migrate an existing application to microservices.
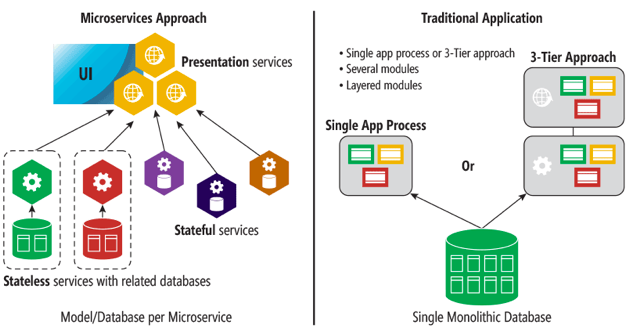
Monolith Architecture Challenges
- Growing codebase.
- Tightly coupled code.
- Long-term commitment to a single technology stack.
- The whole application gets affected by the failure of a single module.
- Scalability issues.
Quantitative Benefits
Let's take a look at a Walmart case study to see the quantitative benefits of migrating to microservices.
Migrating to microservices caused a significant business uplift for the company:
- Conversions were up by 20% literally overnight.
- Mobile orders were up by 98% instantly.
- There was no downtime on Black Friday or Boxing Day (the Black Friday of Canada) and there has been zero downtime since the re-platforming.
- The operational savings were significant, as well. The company moved off of its expensive hardware onto commodity hardware (cheap virtual x86 servers) and saved 40% of the computing power and experienced 20-50% cost savings overall.
Qualitative Benefits
| Areas | Monolith architecture | Microservice architecture |
| Architecture | Represents a single logical program unit. All functions, libraries, and dependencies are located within one application block. | Consists of a series of small services that work independently and communicate with each other. Each service can be used in more than one application. |
| Scalability | The application scales horizontally behind a load balancer. | Each service scales independently and on demand. |
| Agility | Changes to the system lead to the compilation, testing, and deployment of the entire application. | Each service can be changed independently. |
| Development | Based on a single programming language. | Each service can be developed in a different programming language and integration can be done via API. |
| Maintainence | Big and complex source code; difficult to manage. | Many independent modules of source code that are easier to maintain. |
Challenges With Migration
Monolithic legacy systems cannot be changed overnight.
A gradual approach is recommended because new microservices can be tested quickly without interrupting the reliability of the current monolithic structure. Use microservices to create new features through the legacy API.
Modularize the monolithic architecture so that it can still share code and deployments, but move modules into microservices independently if needed.
Migration Strategy
Consider the following refactoring approaches.
1. Incrementally Refactor the Monolithic Application
This is better than a big-bang rewrite. Gradually build a new application consisting of microservices and run it in conjunction with the monolithic application.
Gradually build a new application consisting of microservices and run it in conjunction with the monolithic application.
Over time, the amount of functionality implemented by the monolithic application shrinks until either it disappears entirely or it becomes just another Microservices.
2. New Functionalities Should Be Put in a Standalone Microservice
Strategies that a service can use to access the monolith’s data include:
- Invoke a remote API provided by the monolith.
- Access the monolith’s database directly.
- Maintain its own copy of the data, which is synchronized with the monolith’s database.
3. Split Frontend and Backend
Shrink the monolithic application to split the presentation layer from the business logic and data access layers.
4. Extract Services
Turn existing modules within the monolith into standalone microservices, prioritizing which modules to convert into services.
Start with a few modules that are easy to extract and extract those modules that will have the greatest benefits.

Rank modules by their benefits. It is usually beneficial to extract modules that change frequently.
Extract modules that have resource requirements significantly different from those of the rest of the monolith — for example, turn a module that has an in-memory database into a service that can then be deployed on hosts with large amounts of memory.
Extract modules that implement computationally expensive algorithms since the service can then be deployed on hosts with lots of CPU.
Look for existing coarse-grained boundaries as they make it easier and cheaper to turn modules into services. For example, a module that only communicates with the rest of the application via asynchronous messages. It can be relatively cheap and easy to turn that module into a microservice.
Below is an approach for extracting a module:
- Define a coarse-grained interface (bidirectional API) between the module and the monolith that enables communication between the monolith and the service.
- Turn the module into a free-standing service. Write code to enable the monolith and the service to communicate through an API that uses an inter-process communication (IPC) mechanism.
5. Service Discovery
Each service refers to an external registry holding the endpoints of the other services.
- The client makes a request to a service via a load balancer. The load balancer queries the service registry and routes each request to an available service instance.
- The service registry is a database containing the network locations of service instances.
- A service instance is responsible for registering and deregistering itself with the service registry
- Also, if required, a service instance sends heartbeat requests to prevent its registration from expiring.
Self-Registration Pattern
In the third-party registration pattern, service instances aren’t responsible for registering themselves with the service registry,
The service registrar tracks changes to the set of running instances by either polling the deployment environment or subscribing to events. When it notices a newly available service instance, it registers the instance with the service registry.
The service registrar also deregisters terminated service instances.
Service Deployment
Patterns for service deployment:
- Multiple service instances per host pattern: Provision one or more physical or virtual hosts and run multiple service instances on each one.
- Service instance per virtual machine pattern: Package each service as a virtual machine (VM) image. Each service instance is a VM that is launched using that VM image.
- Service instance per container pattern: Each service instance runs in its own container.
- Containers are a virtualization mechanism at the operating system level.
- A container consists of one or more processes running in a sandbox.
- They have their own port namespace and root filesystem.
Best Practices for Constructing Continuous Deployment Pipeline
- Use one repository per service.
- Each service should have independent CI and Deployment pipelines.
- Plug in all of the toolchain into the DevOps automation platform.
- The sSolution must be tools/environment agnostic.
- Solution needs to be flexible to support any workflow.
- Automation platforms should integrate with all the test automation tools and service virtualization.
- Audits should be in place.
- Compliance should be there in the pipeline by binding certain security checks and acceptance tests.
- Automatic and manual approval gates to support regulatory requirements or general governance processes.
- Provide a real-time view of all the pipelines’ statuses and any dependencies or exceptions.
- Monitoring and logging should be enabled for pipeline automation.
Continuous Deployment Using VSTS
VSTS easily packages app in an automated build and publishes the app in a release.
Challenges
- Publishing (new vs. upgrade).
- Versioning.
Steps
- ARM templates help create the clusters using during the deployment.
- Add different publishing profiles to separate environments (prod, test, dev, etc.).
- In order to create the Azure Resource Group containing the cluster from the ARM template, VSTS will need a secure connection to the Azure subscription.
- This connection is service-principal-based, so you need to have an AAD backing your Azure subscription and you need to have permissions to add new applications to the AAD.
- If you don’t have an AAD backing your subscription or can’t create applications, you can manually create the cluster in your Azure subscription.
Things We Can Do
- Create release definitions for different environments.
- Continuous deployment.
- Create/update clusters.
Application Upgrade
Rolling Upgrades
- The upgrade is performed in stages. At each stage, the upgrade is applied to a subset of nodes in the cluster, called an update domain.
- The application remains available throughout the upgrade.
Non-Rolling Upgrades
- The upgrade is applied to all nodes in the cluster, which is the case when the application has only one update domain.
- Not recommended, since the service goes down and isn't available at the time of upgrade.
Health Checks During Upgrades
- Whether the application package was copied correctly.
- Whether the instance was started.
- Service fabric evaluates the health of the application through the health that is reported on the application.
- Service fabric further evaluates the health of the application services by aggregating the health of their children, such as the service replica.
Service Monitoring
Azure Service Fabric introduces a health model that provides rich, flexible, and extensible health evaluation and reporting.

- Obtain health information and correct potential issues before they cascade.
- Real-time monitoring of the state of the cluster and the services running in it.
Azure Service Fabric provides the following functionalities for health monitoring:
- Health store: Keeps health-related information about entities in the cluster for easy retrieval and evaluation.
- Health entities:
- The health entities are organized in a logical hierarchy that captures interactions and dependencies among different entities.
- The entities and hierarchy are automatically built by the health store based on reports received from Service Fabric components
- The health entities mirror the Service Fabric entities.
- Health states: OK, warning, and error.
- Health policies: cluster health policy, application health policy, service type health policy.
- Health evaluation.
- Health reporting.
Scaling Microservices
The scalability options for Azure Service fabric are the following.
- Stateless service:
- Defining a higher number of service instance counts (two or more).
- Each of these load-balanced instances gets deployed to different nodes in the cluster.
- Stateful service:
- Stateful services can divide the load among its partitions or named service instances.
- The partitions are just the separate service instances running with replicas on various nodes in the clusters.
- Each of the partitions works on a subset of the total state managed by the stateful service.
- Partitioning can be achieved by:
- Named service instances: A specific named instance of a service type deployed to ASF.
- Implementing a partitioning scheme for the service.
- Singleton: This indicates that the service doesn't need partitioning.
- Named: The service load can be grouped into subsets identified by a predefined name.
- Ranged partitions: The service load is divided into partitions identified by integer range, a low and a high key and a number of partitions (n).
Testing Microservices
- Azure Service fabric has fault analysis service that performs the following testing:
- Induce meaningful faults and run complete test scenarios against applications. For example:
- Restart a node to simulate any number of situations where a machine or VM is rebooted.
- Service-to-service communication.
- Chaos test.
- Failover test.
- Move a replica of the stateful service to simulate load balancing, failover, or application upgrade.
- Invoke quorum loss on a stateful service to create a situation where write operations can't proceed because there aren't enough "back-up" or "secondary" replicas to accept new data.
- Invoke data loss on a stateful service to create a situation where all in-memory state is completely wiped out.
- Simulating and generating failures that might occur in real-world scenarios.
- Generate correlated failures.
- Unified experience across various levels of development and deployment.
- Induce meaningful faults and run complete test scenarios against applications. For example:
Tools for load testing microservices include SoapUI and JMeter. The following are a couple of testability scenarios.
Service-to-Service Communication
Service fabric provides built-in service communication components which can be used to test interactions between services
Chaos Test Scenario
This generates faults across the entire Service Fabric cluster and compresses faults generally seen in months or years to a few hours. Faults include:
- Restart a node.
- Restart a deployed code package.
- Remove a replica.
- Restart a replica.
- Move a primary replica (optional).
- Move a secondary replica (optional).
Failover Test
Tests the effect of failover on a specific service partition while leaving the other services unaffected. Faults include:
- Restart a deployed code package where the partition is hosted.
- Remove a primary/secondary replica or stateless instance.
- Restart a primary secondary replica (if a persisted service).
- Move a primary replica.
- Move a secondary replica.
- Restart the partition.
Using Azure Service Fabric for Microservices Implementation
Azure Service fabric Runs on Azure, on-premises or in any cloud (even in other third-party hosted clouds like AWS). It supports Windows or Linux. It runs any Windows application in your cluster, not only Service Fabric-aware apps.

Azure Service fabric improves reliability by adding redundancy into the application deployments over multiple nodes (Virtual Machines). The service fabric cluster is the group of five or more VMs that provide a guarantee against node-level failures.
Azure service fabric can be used for any service types.
Stateless Services
- A service that doesn't hold any state between its requests and responses.
- We need either caching or external storage to hold the state.
- Configure two or more instances for any stateless service. These instances are automatically load-balanced.
- Each of these instances will be deployed to different nodes in the cluster.
- If any instance failure is detected, runtime creates a new instance automatically on another node in the same cluster
Stateful Services
- A stateful service is modeled as a set of one primary and many active secondary replicas.
- These replicas consist of two things: an instance of the application code and the state of the VM.
- Co-location of code and state data makes it powerful as it results in low latency.
- All the data read and write operations are performed at the primary replica, which gets replicated to the active secondary.
- If any replica goes down, Service Fabric Runtime automatically replaces it with a new replica on another node.
- In case the primary fails, the secondary replica takes over as the primary and a brand new replica gets added as a secondary.